Python Portfolio
Here, you can find all of my Python projects (continually updated with new and/or tuned projects)
Here, you can find all of my Python projects (continually updated with new and/or tuned projects)
Masters project to predict which tweets are about real disasters from the Kaggle Competition "Natural Language Processing with Disaster Tweets". Coming soon...
Masters project to identify metastatic tissue in histopathologic scans of lymph node sections from the Kaggle competition "Histopathologic Cancer Detection". Coming soon...
Masters project where I create a Generative Adversarial Network (GAN) for the "I’m Something of a Painter Myself" Kaggle Competition. Coming soon...
Masters project using Non-Matrix Factorization for topic modeling of BBC news. From Kaggle Competition. Coming soon...

Used Sentiment Analysis to build a predictor that classifies positive and negative movie reviews. Used a dataset of 50,000 reviews provided by IMDb. Uses Python's Pickle Module, SQLite, and Flask for a web application to prompt a user for a review, make a prediction, and close the application without having to reload the dataset. Real world usage of this project could include apps for spam detection or recommendaiton systems.

Starting with a single-layer neural network structure and connecting multiple neurons together, this project dove into the basics behind a Multilayer Artificial Neural Network and was built from scratch. This specific Multilayer Perceptron (MLP) and was designed to recognize handwritten numbers from the MNIST Database of Handwritten Digits. I classified the data and implemented backpropagation to train the MLP.
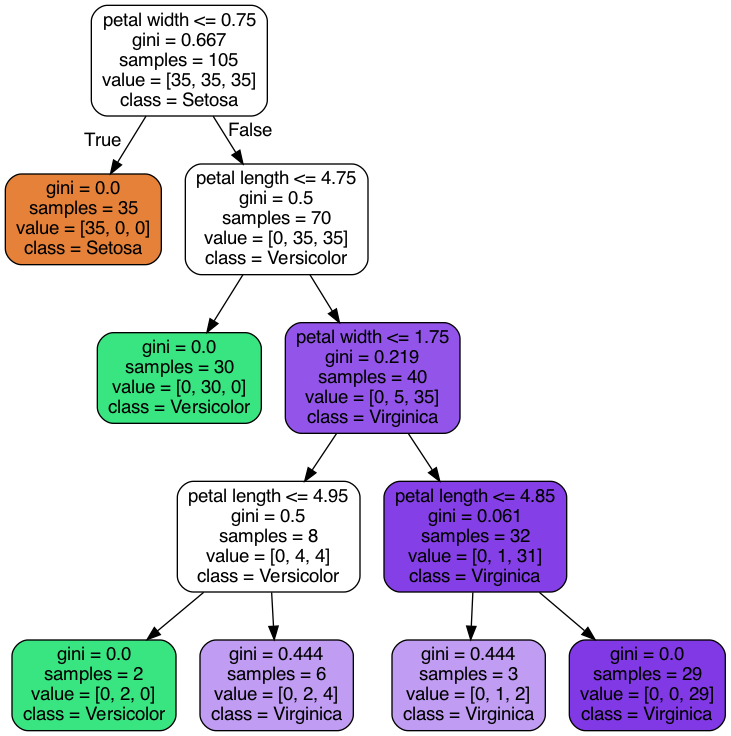
Expanding on Simple Artifical Neurons, this project expands on the algorithms for classification and provides examples, primarily using the library scikit-learn. First, I initialized the Perceptron and Adaline models and then converted them into an algorithm for logistic regression. Next, I tracked overfitting through Regularization and then used SVM's to classify different flowers and initialize the gradient descent version of Perceptron, Logistic Regression, and SVM with a default parameter. I then used a Kernel SVM to solve linearly inseparable data and find separating hyperplanes. Next I made a decision tree (pictured above). Lastly, I implemented a K-Nearest neighbors (KNN) model using the Euclidean distance metric.
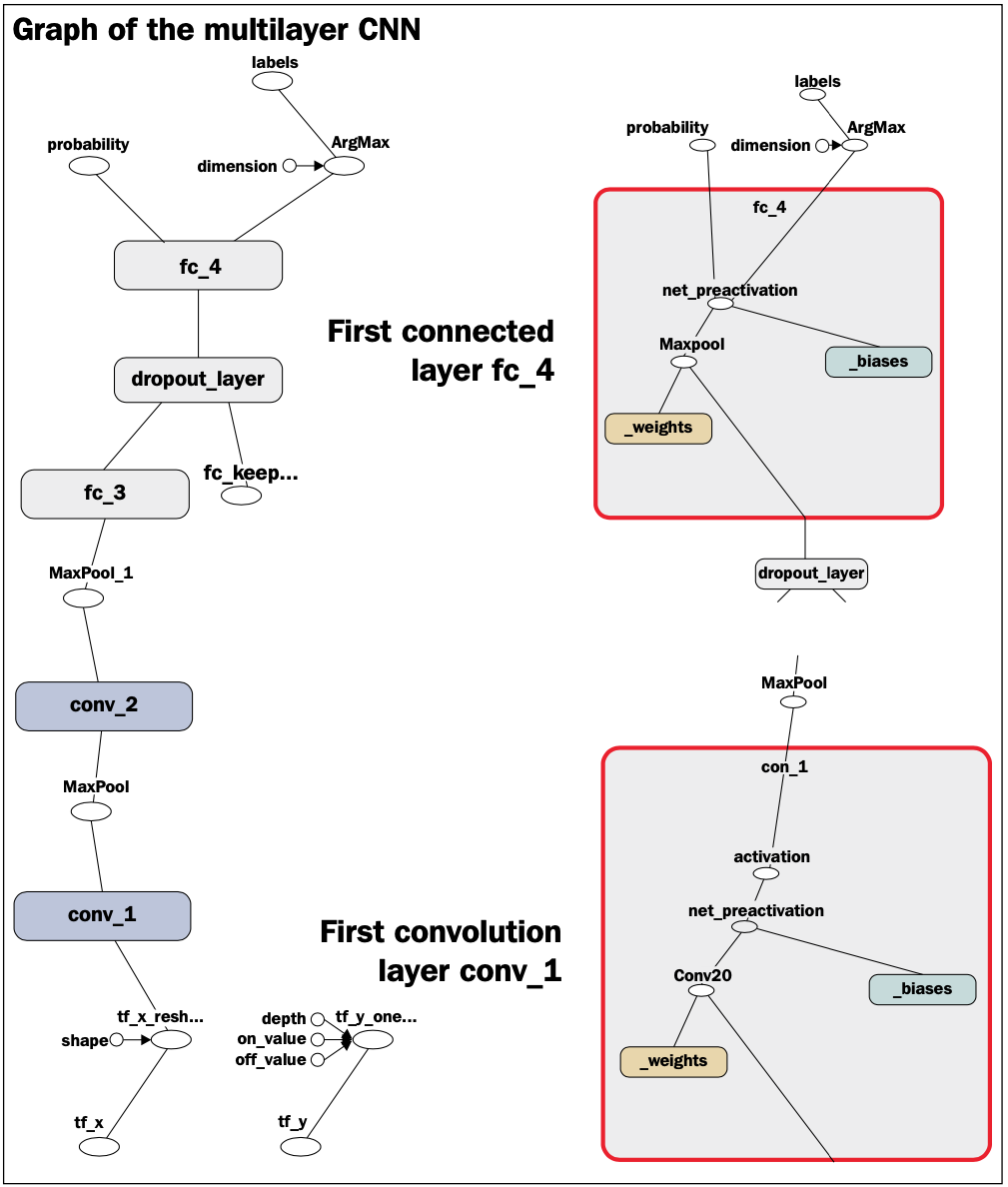
Covers CNN's and explores the base of CNN architecture. Defines convolution operation and then impolements 1D and 2D implmentations. Goes in depth about max- and mean-pooling. At the end, builds a deep convolutional neural network and is implemented using the TensorFlow core API along with TensorFlow Layers API to apply CNNs for image classification.
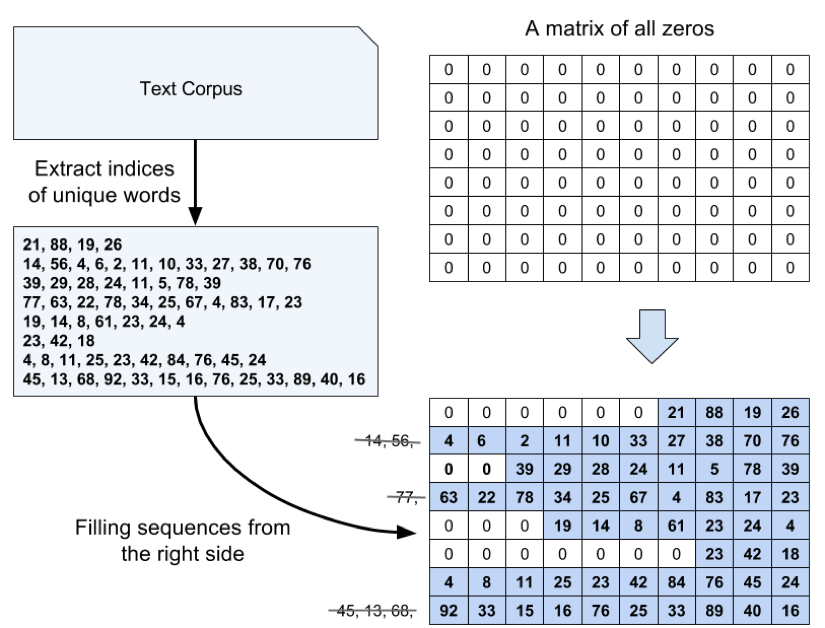
Used a many-to-one architecture to construct an RNN for Sentimemt Analysis. Used the same dataset from the movie review classifier project. The first half of the dataset is training data and second half is for testing. Started with building the class constructor, then added build, train, and predict methods. I instantiated the SentimentRNN class and trained the model for 40 epochs using input from the training data. Last, used the model to predict the class labels on the test set as well as returning the prediciton probabilities.
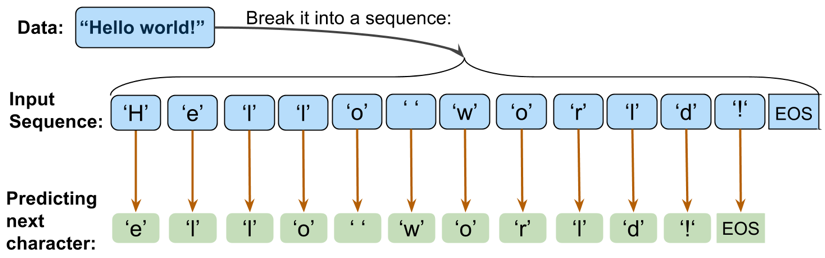
Built an RNN model with the input as a text document. Goal is to generate new text similar to the input document. I processed data by creating a dataset to represent unique characters, made a dictionary to map each character to an integer, and another dictionary that performed reverse mapping. I converted text to a NumPy array of integers. Then reshaped into batches of sequences and created a batch_generator function. Built a CharRNN class with a build method that used one-hot encoding instead of embedding layer, a train method, and sample method (similar to predict method in Sentiment Analysis RNN). I called a CharRNN instance to train the data, then sampled and returned a text document. The original data is in old English which makes the text a little more interesting.
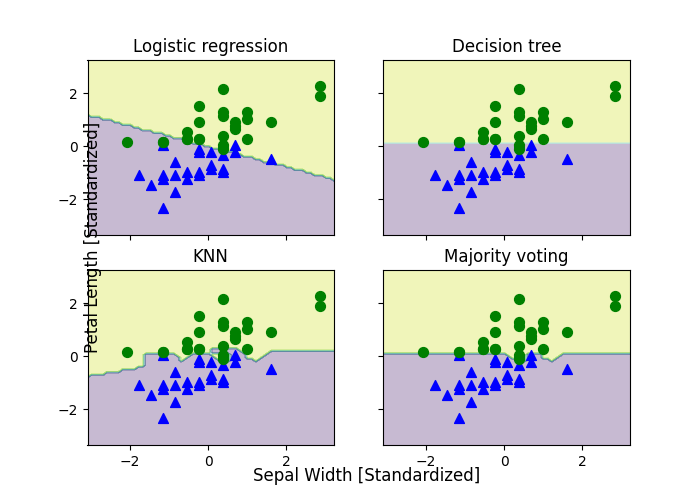
This project is an introduction to combining different methods of learning algorithms, which in turn creates more accurate and reliable predictions than one single learner. I started by implementing the probability mass function and then moved onto combining classifiers by Majority Votes and implemented a Majority Vote Classifier. I used this class to make predictions based off the same Iris dataset as before and trained it on 3 different classifiers: Logistic Regression, Decision Tree Classifier, and the K-Neighbors Classifier. Next, I evaluated and tuned the Ensemble Classifier by computing ROC Curves and standardizing the training set for visual consistency of the decision tree (pictured above). Next, I conducted Bagging and built an ensemble of classifiers from bootstrap samples. Last, I used leveraged the weak learners through Adaptive Boosting.
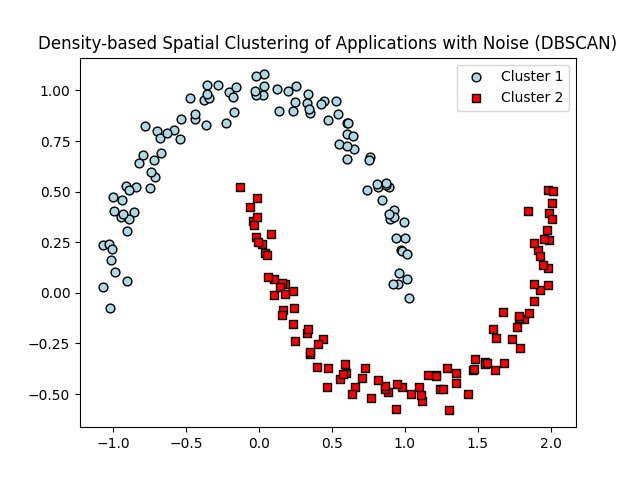
This project takes a look at three different clustering algortihms: K-Means Clustering, Agglomerative Hierarchical Clustering, and Density-based Spatial Clustering of Applications with Noise (DBSCAN). K-Means is an unsupervised method and clusters samples into spherical shapes based on a specific number of cluster centroids. I used two performance metrics (the elbow method and silhouette analysis) to quantify the quality of the clustering. Hierarchical clustering doesn't require specific number of clusters and is illustrated by a Dendrogram. This helps visualize the results. The DBSCAN groups points based on the densisties of the samples and has the capability to handle outliers and identifying clusters with non-globular shapes.
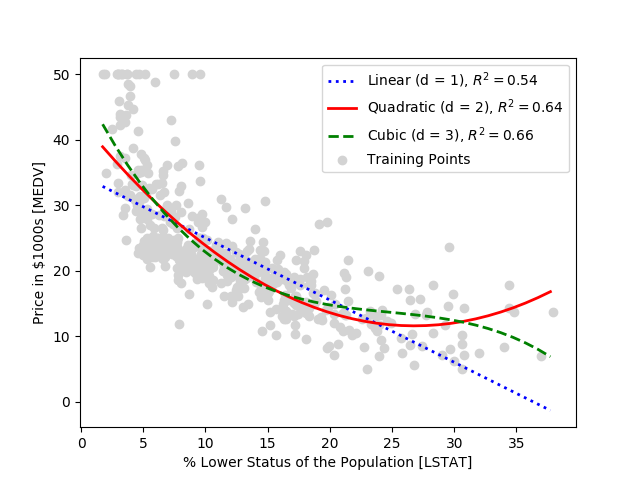
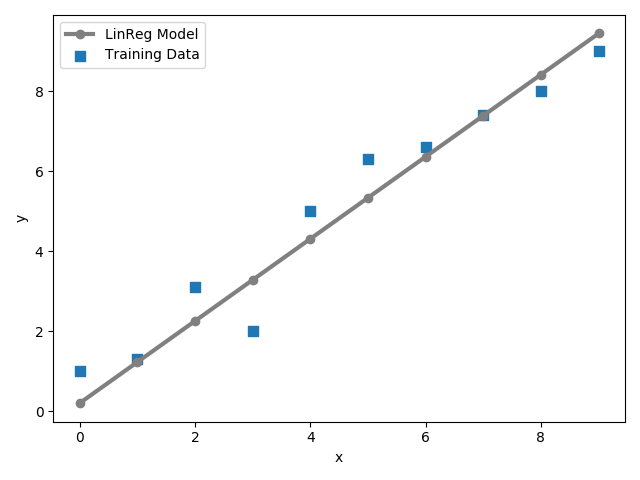
Primarily using Scikit-Learn, this project goes into depth on modeling linear relationships between target and response variables to make predictions on a continuous scale. First, I introduced a Gradient-Descent Linear Regression and implemented an Orinary Least Squares (OLS) Regression Model. Next, I used RANSAC as an approach to deal with the outliers in the dataset and I estimated the coefficient of the regression model. Finally, I used polynomial feature transformation and random forest regressors to model nonlinear relationships between variables.
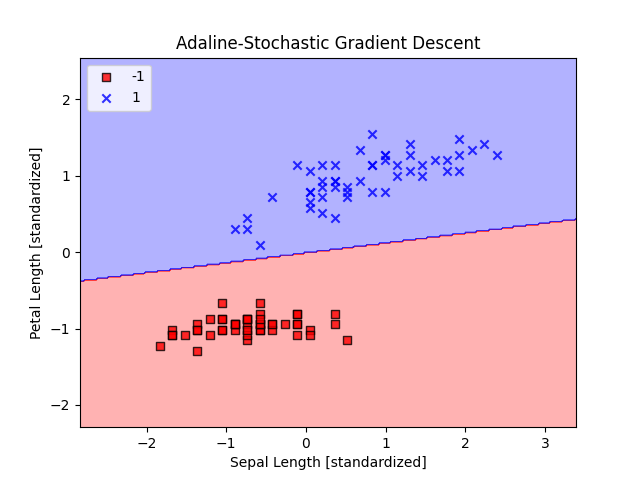
This project looks to classify flowers into two categories, 'Setosa' and 'Versicolor', based off of variables 'Sepal Length' and 'Petal Length'. I programmed two simple artifical neurons and plotted their respective decision regions. It is broken up into two sections: Perceptron and Adaline. For the perceptron, I initialized the weights and then updated the weights using a unit step function after computing the output. I used the same process for Adaline, except updated the weights using a linear activation function.
This project aimed to introduce the TensorFlow library and convey its ability to define and train large, multilayer neural networks efficiently, as well as how the TensorFlow API can build complex ML and Neural Networking models. To start, I programmed in the low-level TF API. Next, I used TF Layers and Keras to build the multilayer neural netowrk and learned how to build these models using the APIs.
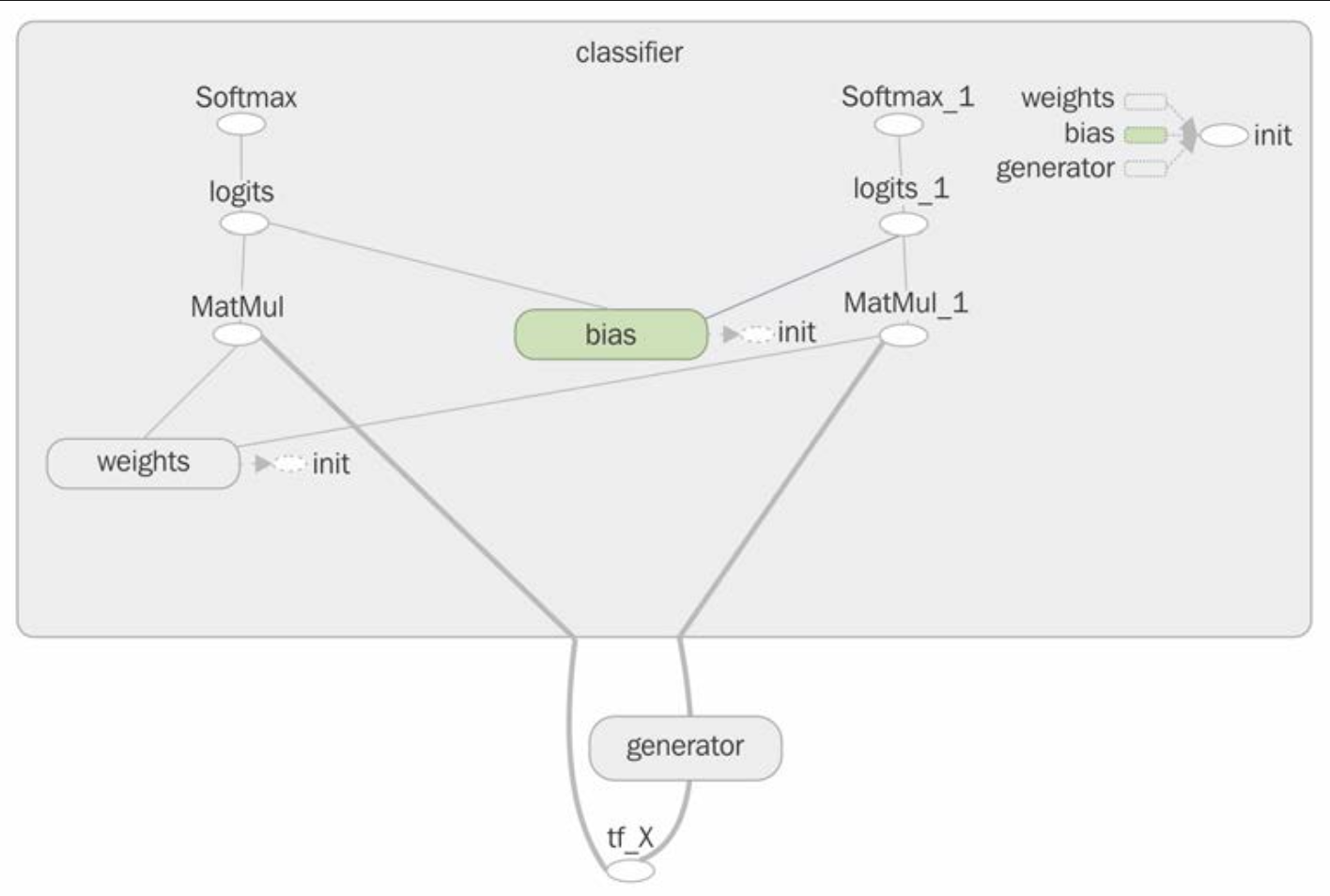
Covers key features and concepts of TensorFlow such as computation graphs (implmentation and visualization using TensorBoard), launching a graph in a session environment, placeholders and variables, and evaluating tensors and executing operators. Touches on transforming tensos using transpose, reshape, split, and concat.
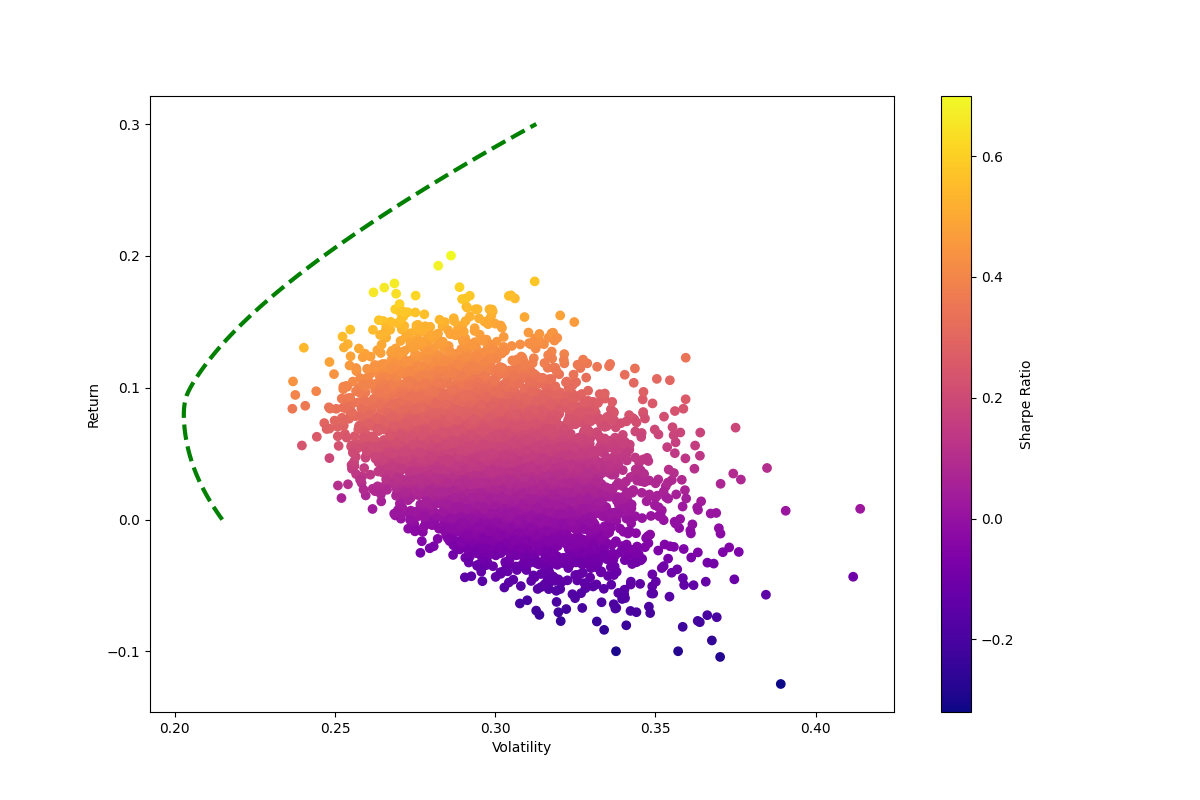
Using Pandas, Numpy, Scipy, and MatPlotLib, I was able to grab a combination of 12 stock tickers' chart data, set the portfolio allocation percentage, and track the performance of both the individual stocks as well as the entire portfolio. I then plotted a Sharpe Ratio and a Marcowitz Portfolio Optimization Model to visualize the risk to return.
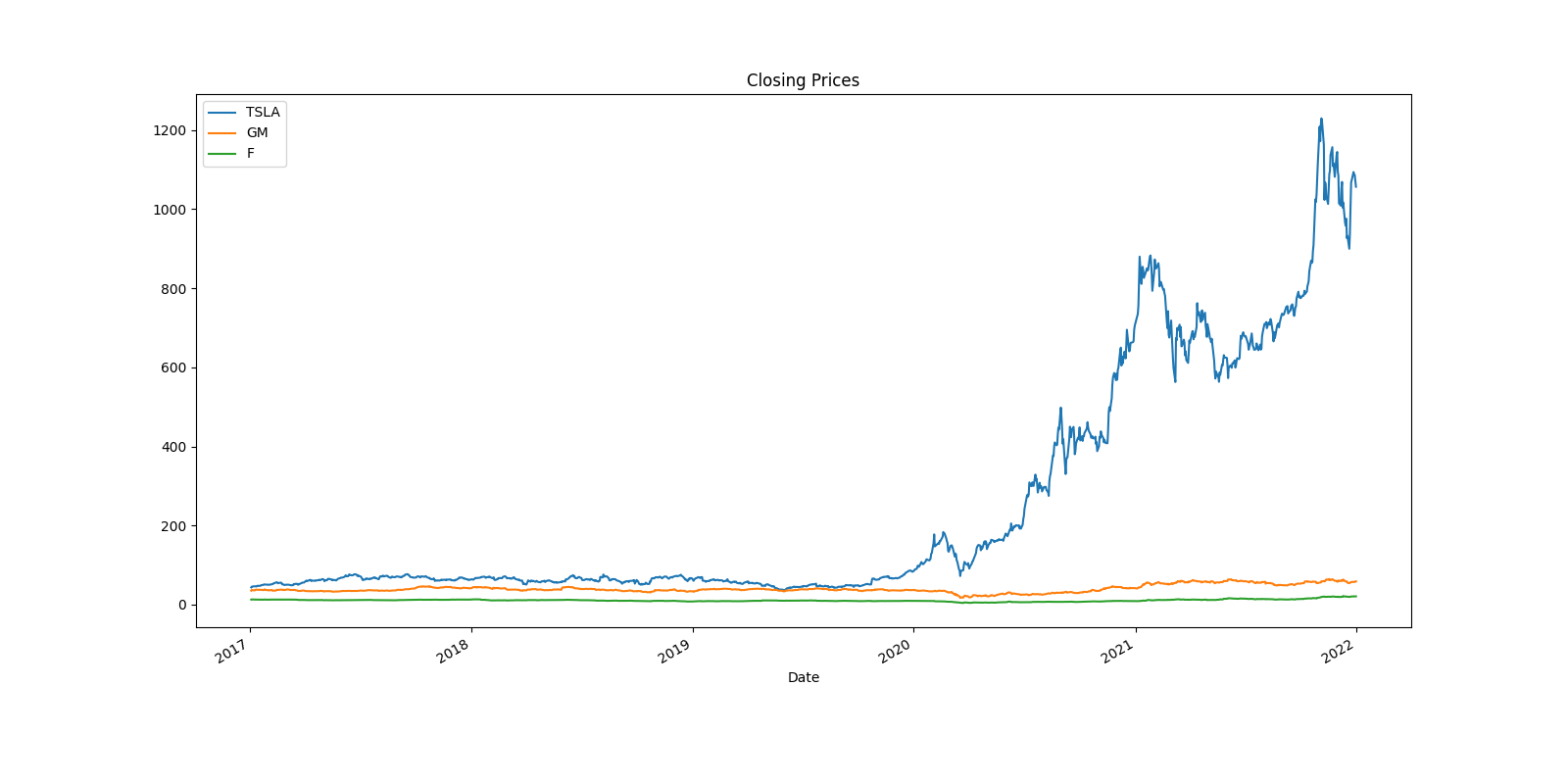
One of my earliest Python projects, this is a simple visualization of the stock performance for Ford, Tesla, and GM, as well as their volume over time. The data is stored in a CSV file for their respective stock. The dates for the CSV are from January 1st, 2017 to January 1st, 2022. It also prints out the perfomance from the latest close.
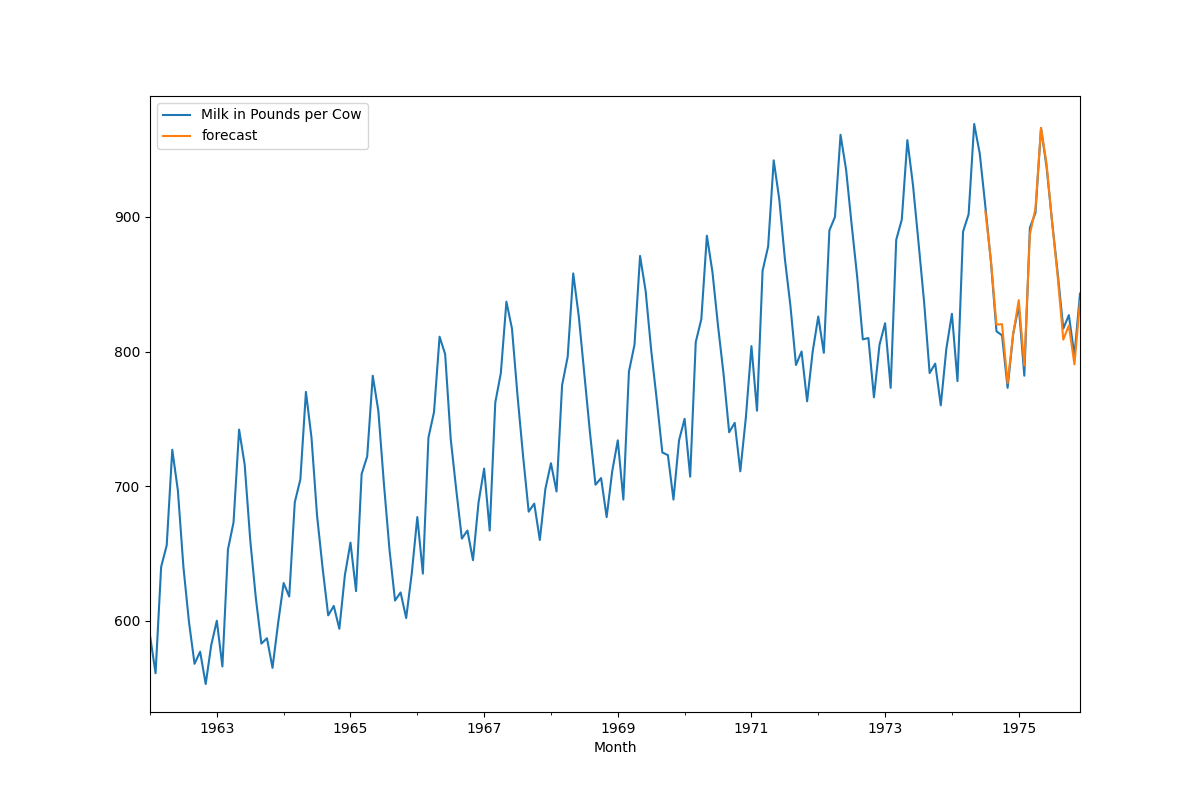
In my Financial Econometrics course, I learned about many different modeling methods and one of my favorite was the ARIMA model. Using my knowledge from the course and the help of the internet, I was able to model the monthly milk production in cows and plot a forecasted prediction alongside actual data. I did this by creating an ETS Plot, running an Augmented Dicky-Fuller Test, creating an Autocorrelation plot, and then making a seasonal ARIMA model.

In DNA, I coded a program that analyzed a DNA sequence, found the number of STR's, and returned who the sequence belongs to. The database that the sequence is matched to has a column of names and then columns of the number of STR's in that person's DNA. The program will match the number of each STR in that sequence to the corresponding person, which then returns who's sequence that is.